들어가며
데이터 엔지니어링의 세계는 빠르게 변화하고 있으며, 다양한 데이터 소스와 방대한 데이터 양을 효율적으로 관리하고 분석할 수 있는 도구의 필요성이 날로 커지고 있습니다. 이러한 요구를 충족시키기 위해 등장한 솔루션 중 하나가 Snowflake입니다. 본 글에서는 Snowflake의 주요 기능과 데이터 엔지니어가 이를 어떻게 활용할 수 있는지, 그리고 비용 구조에 대해 자세히 살펴보겠습니다.
Snowflake에 대해
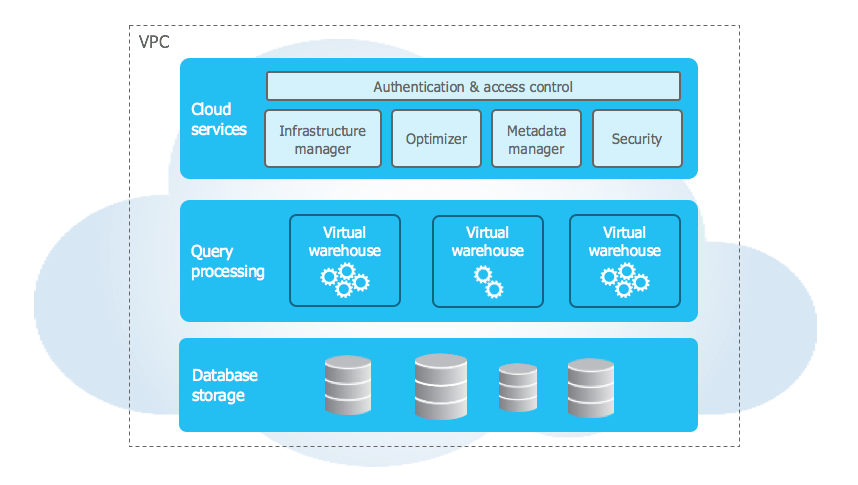
Snowflake는 클라우드 기반의 데이터 웨어하우스 플랫폼으로, 데이터 저장, 처리, 분석을 하나의 통합된 환경에서 제공하는 서비스입니다. 전통적인 데이터 웨어하우스와 달리 Snowflake는 클라우드의 유연성과 확장성을 최대한 활용하여 데이터 엔지니어링 작업을 보다 효율적이고 효과적으로 수행할 수 있게 해줍니다.
주요 특징
- 클라우드 네이티브 아키텍처: AWS, Azure, Google Cloud 등 주요 클라우드 플랫폼과 통합되어 있어 배포와 확장을 더욱 쉽게 수행할 수 있습니다.
- 자동 스케일링: 사용자 요구에 따라 자동으로 컴퓨팅 리소스를 확장하거나 축소하여 비용 효율성을 극대화합니다.
- 데이터 공유: 손쉽게 데이터 세트를 공유할 수 있는 기능을 제공하여 협업을 강화합니다.
- 보안 및 컴플라이언스: 다양한 보안 기능과 컴플라이언스 표준을 준수하여 데이터 보호를 보장합니다.
데이터 엔지니어는 Snowflake를 통해 데이터를 효율적으로 적재, 변환, 저장, 분석할 수 있습니다. 다음은 Snowflake의 주요 활용 방안입니다.
1. 데이터 통합 및 ETL/ELT 프로세스
Snowflake는 다양한 데이터 소스와의 통합이 용이하며, 대용량 데이터를 빠르게 적재할 수 있는 기능을 제공합니다. 이를 통해 데이터 엔지니어는 ETL(Extract, Transform, Load) 또는 ELT(Extract, Load, Transform) 프로세스를 효율적으로 설계하고 구현할 수 있습니다.
- 스테이징 영역: 외부 데이터 소스에서 데이터를 가져와 임시로 저장할 수 있는 스테이징 영역을 제공합니다.
- 자동화된 데이터 적재: Snowpipe와 같은 도구를 사용하여 실시간으로 데이터를 자동으로 적재할 수 있습니다.
2. 데이터 변환 및 정제
Snowflake의 강력한 SQL 처리 능력을 활용하여 데이터 변환 및 정제를 손쉽게 수행할 수 있습니다. 데이터 엔지니어는 복잡한 데이터 파이프라인을 구축하지 않고도 데이터 무결성을 유지하며 쉽게 데이터를 변환할 수 있습니다.
- CTE(Common Table Expressions): 복잡한 쿼리를 간결하게 작성할 수 있습니다.
- 사용자 정의 함수(UDF): 복잡한 변환 로직을 재사용 가능한 함수로 정의할 수 있습니다.
3. 고성능 분석 및 쿼리 처리
Snowflake는 고성능의 쿼리 처리 속도를 제공하여 대규모 데이터 세트에 대한 신속한 분석을 가능하게 합니다. 데이터 엔지니어는 Snowflake를 이용하여 빠르게 데이터를 탐색하고 필요한 인사이트를 도출할 수 있습니다.
- 멀티 클러스터 아키텍처: 동시 사용자가 많더라도 성능 저하 없이 빠른 쿼리 응답을 보장합니다.
- 자동 최적화: 쿼리 계획을 자동으로 최적화하여 효율적인 데이터 처리를 지원합니다.
4. 데이터 거버넌스 및 보안 관리
Snowflake는 데이터 거버넌스와 보안 관리 기능을 제공하여 데이터 엔지니어가 데이터의 접근 권한을 세밀하게 제어할 수 있도록 합니다.
- 역할 기반 접근 제어(RBAC): 사용자별로 세분화된 접근 권한을 설정할 수 있습니다.
- 데이터 암호화: 저장 데이터와 전송 데이터를 모두 암호화하여 안전하게 보호합니다.
Snowpark
Snowpark는 Snowflake에서 제공하는 프로그래밍 프레임워크로, 데이터 엔지니어와 데이터 사이언티스트가 익숙한 프로그래밍 언어를 사용하여 Snowflake 내에서 직접 데이터 처리 및 분석 작업을 수행할 수 있게 해줍니다. 현재 Snowpark는 Java, Scala, Python을 지원하며, 이를 통해 SQL 뿐만 아니라 복잡한 데이터 처리 로직을 구현할 수 있습니다.
주요 특징
- 통합된 개발 환경: Snowpark를 사용하면 ETL 프로세스, 데이터 변환, 분석 작업 등 데이터 파이프라인의 모든 단계를 Snowflake 플랫폼 내에서 구현할 수 있습니다. 이는 데이터 이동을 최소화하고 보안을 강화하며, 전체 프로세스의 효율성을 높입니다.
- 다양한 프로그래밍 언어 지원: Java, Scala, Python을 지원함으로써 데이터 엔지니어들이 익숙한 언어로 쿼리 및 데이터 분석 코드를 작성할 수 있습니다. 이를 통해 학습 곡선을 낮추고 Snowflake 컴퓨팅 엔진을 이용해 생산성을 높일 수 있습니다.
- 최적화된 성능: Snowpark는 Snowflake의 분산 처리 엔진을 활용하여 대규모 데이터셋에 대해 고성능 처리를 제공합니다. 또한, 지연 실행방식을 채택하여 쿼리 최적화를 수행합니다.
- UDF 지원: 복잡한 로직을 UDF로 구현하여 재사용성을 높이고, 이를 SQL 쿼리 내에서 직접 활용할 수 있습니다.
- 머신러닝 통합: Snowpark for Python을 통해 데이터 준비부터 모델 학습, 배포까지 전체 ML 파이프라인을 Snowflake 내에서 구현할 수 있습니다.
Snowpark 사용 예시
Snowpark for Python을 사용하여 데이터를 읽고 필터링, 그룹화, 집계 작업을 수행한 뒤 새로운 테이블로 저장하는 예시 코드입니다.
from snowflake.snowpark import Session
import snowflake.snowpark.functions as F
# Snowflake 연결 설정
session = Session.builder.configs(connection_parameters).create()
# 데이터 프레임 생성
df = session.table("my_table")
# 데이터 변환
transformed_df = df.filter(F.col("column_a") > 100) \
.groupBy("column_b") \
.agg(F.sum("column_c").alias("total_c"))
# 결과 저장
transformed_df.write.save_as_table("result_table")
Snowflake Python API
Snowflake Python API는 데이터 엔지니어링, Snowpark, 머신러닝, 앱 개발 등에서 모든 Snowflake 리소스와 상호 작용하기 위한 통합 Python 인터페이스입니다. 모든 Snowflake 리소스를 Python만으로 관리할 수 있는 포괄적인 인터페이스를 제공합니다. 이를 통해 개발 과정을 단순화할 수 있습니다.
Snowflake Python API는 모든 Snowflake Python 라이브러리 (connector, core, snowpark, ml 등)를 통합하였습니다. API를 사용하여 리소스의 변경 사항을 관리하고, Snowflake에서 코드 및 인프라 배포를 자동화할 수 있습니다.
주요 특징
- 직관적인 connection 관리: 데이터베이스 연결을 쉽게 설정하고 관리할 수 있습니다.
- SQL 쿼리 실행: Python 코드 내에서 SQL 쿼리를 직접 실행할 수 있습니다.
- 파라미터화된 쿼리: SQL 인젝션 방지 및 쿼리 최적화를 위해 파라미터화된 쿼리를 지원합니다.
- 대용량 데이터 처리: 대용량 데이터의 효율적인 로드와 언로드를 지원합니다.
- 비동기 쿼리 실행: 장시간 실행되는 쿼리를 비동기적으로 처리할 수 있습니다.
- 보안 기능: 다양한 인증 방식과 암호화를 지원하여 보안을 강화합니다.
Snowflake Python API 사용 예시
Python API를 사용하여 SELECT 쿼리를 실행하는 예시 코드입니다.
import snowflake.connector
# Snowflake 연결 설정
conn = snowflake.connector.connect(
account='account',
user='username',
password='password',
warehouse='warehouse',
database='database',
schema='schema'
)
# 커서 생성
cur = conn.cursor()
# SQL 쿼리 실행
cur.execute("SELECT * FROM my_table")
# 결과 가져오기
for row in cur:
print(row)
# 연결 종료
cur.close()
conn.close()
Python API 기능 활용
파라미터화된 쿼리
SQL 인젝션을 방지하고, 쿼리 성능을 최적화하기 위해 파라미터화된 쿼리를 사용할 수 있습니다.
cur.execute(
"SELECT * FROM customers WHERE region = %s AND sales > %s",
('EMEA', 10000)
)
대용량 데이터 로드
write_pandas 메서드를 이용하여 Pandas DataFrame을 Snowflake 테이블에 효율적으로 로드할 수 있습니다.
import pandas as pd
from snowflake.connector.pandas_tools import write_pandas
df = pd.DataFrame({'col1': [1, 2], 'col2': ['a', 'b']})
success, nchunks, nrows, _ = write_pandas(conn, df, 'my_table')
비동기 쿼리 실행
장시간 실행되는 쿼리를 비동기적으로 처리할 수 있습니다.
async_cur = conn.cursor(snowflake.connector.DictCursor)
async_cur.execute_async("SELECT * FROM large_table")
query_id = async_cur.sfqid
...
# 결과 확인
async_cur.get_results_from_sfqid(query_id)
results = async_cur.fetchall()
Snowflake Pandas API
데이터 분야에서 Python과 Pandas 라이브러리는 필수적인 도구로 자리잡았습니다. Snowflake Pandas API를 이용하면 데이터 엔지니어들이 익숙한 Pandas 문법을 사용해 Snowflake 내의 대규모 데이터를 효율적으로 처리할 수 있게 됩니다. Pandas DataFrame과 유사한 방식으로 Snowflake의 테이블을 다룰 수 있으며, 대규모 데이터셋에 대해 Snowflake의 분산 처리 능력을 함께 활용할 수 있습니다.

출처: 2024 Snowflake Word Tour Seoul
주요 특징
- 익숙한 Pandas 문법: Snowflake Pandas API는 기존 Pandas 사용자들에게 익숙한 메서드와 속성을 제공합니다. 예를 들어
head(),tail(),groupby(),merge()등의 메서드를 그대로 사용할 수 있습니다. - 대규모 데이터 처리: Pandas의 한계인 메모리 제한을 극복하고, Snowflake의 분산 처리 능력을 활용하여 테라바이트 규모의 데이터도 효율적으로 처리할 수 있습니다.
- 지연 실행 (Lazy Evaluation): 쿼리 최적화를 위해 지연 실행 방식을 채택하여 실제 데이터가 필요한 시점에 최적화된 쿼리가 실행됩니다.
- Snowflake 기능과의 통합: Snowflake의 고유한 기능들 (Time Travel, Data Sharing 등)을 Pandas 인터페이스를 통해 쉽게 활용할 수 있습니다.
- ETL 프로세스 간소화: 데이터 추출, 변환, 로드 과정을 하나의 Python 스크립트 내에서 Pandas 문법으로 처리할 수 있어 ETL 프로세스가 간소화됩니다.
Snowflake Pandas API 사용 예시
Snowflake 테이블에서 데이터를 읽어와 그룹화 및 집계 작업을 수행한 뒤 다시 Snowflake 테이블로 처리하는 예시 코드입니다.
import snowflake.pandas as spd
# Snowflake 연결 설정
conn = spd.connect(account='account',
user='username',
password='password',
warehouse='warehouse',
database='database',
schema='schema')
# Snowflake 테이블을 DataFrame으로 로드
df = spd.read_sql("SELECT * FROM table", conn)
# 데이터 처리
result = df.groupby('category').agg({'sales': 'sum', 'quantity': 'mean'})
# 결과를 Snowflake 테이블로 저장
result.to_sql('result_table', conn, if_exists='replace', index=False)
주의사항 및 최적화
1. 메모리 사용: 대규모 데이터셋을 다룰 때에는 메모리 사용에 주의해야 합니다. 가능한 한 Snowflake 내에서 데이터를 처리하고, 필요한 결과만 로컬로 가져오는 것이 좋습니다.
2. 성능 최적화: 복잡한 연산의 경우 순수 SQL이나 Snowflake의 내장 함수를 사용하는 것이 더 효율적일 수 있습니다.
3. 비용 관리: Snowflake의 사용량 기반 과금 모델을 고려하여 쿼리 최적화와 비용 효율성을 고려하며 API를 사용해야 합니다.
4. 데이터 타입: Snwoflake와 Pandas 간의 데이터 타입 차이를 이해하고, 필요에 따라 적절한 변환을 수행해야 합니다.
Snowflake Python API와 Pandas API
사용 빈도와 선호도
- Snowflake Python API는 더 오래되고 널리 사용되는 방식입니다. 데이터베이스 관리, ETL 프로세스, 세밀한 제어가 필요한 작업에 주로 사용됩니다.
- Snowflake Pandas API는 비교적 최근에 도입되었지만 데이터 분석가와 데이터 사이언티스트들에게 인기를 얻고 있습니다. 특히 대규모 데이터 분석과 변환 작업, ML을 위한 데이터 전처리 작업 등에 유용합니다.
선택 기준
Snowflake의 비용 구조
Snowflake는 사용한 만큼 지불하는 사용량 기반 과금 모델을 채택하고 있습니다. 이는 사용자가 필요한 만큼의 리소스를 사용하고, 사용한 만큼만 비용을 지불하는 방식으로 비용 효율성을 극대화할 수 있습니다. Snowflake의 주요 비용 요소는 다음과 같습니다.
1. 컴퓨팅 비용
Snowflake는 컴퓨팅 리소스를 사용한 만큼 비용을 부과합니다. 컴퓨팅 리소스는 주로 웨어하우스(virtual warehouses)라고 불리는 컴퓨팅 클러스터에 의해 제공됩니다.
- 웨어하우스 크기: XS부터 6XL까지 다양한 크기의 웨어하우스를 선택할 수 있으며, 크기에 따라 시간당 비용이 달라집니다.
- 사용 시간: 웨어하우스가 활성화되어 있는 시간 동안만 비용이 발생하며, 사용하지 않을 때는 자동으로 중지하여 비용을 절감할 수 있습니다.
2. 저장 비용
저장된 데이터의 양에 따라 비용이 산정됩니다. Snowflake는 압축된 형태로 데이터를 저장하므로, 실제 저장 비용은 데이터의 크기와 압축률에 따라 달라집니다.
- 영구 저장: 데이터를 장기적으로 보관하는 데 필요한 비용을 지불합니다.
- 단기 저장: 최근에 사용된 데이터를 빠르게 접근할 수 있도록 저장하는 데 필요한 비용을 지불합니다.
3. 데이터 전송 비용
데이터를 외부 시스템으로 전송하거나 Snowflake 내에서 데이터 공유를 할 때 발생하는 비용입니다. 이는 주로 데이터의 양과 전송 빈도에 따라 변동됩니다.
4. 서비스 비용
추가적인 서비스나 기능을 사용할 경우 별도의 비용이 발생할 수 있습니다. 예를 들어, Snowpipe를 통한 실시간 데이터 적재나 데이터 공유 기능 등을 사용할 경우 추가 비용이 부과될 수 있습니다.
결론
Snowflake는 클라우드의 강력한 인프라를 활용하여 데이터 엔지니어에게 유연하고 확장 가능한 데이터 웨어하우징 솔루션을 제공합니다. 손쉬운 데이터 통합, 고성능 쿼리 처리, 효율적인 비용 구조 등 다양한 장점을 통해 데이터 엔지니어링 작업을 혁신적으로 개선할 수 있습니다. 또한, 사용량 기반 과금 모델을 통해 비용 효율성을 높일 수 있어 기업의 데이터 전략을 효과적으로 지원할 수 있습니다. Snowflake를 도입함으로써 데이터 엔지니어는 더욱 생산적이고 전략적인 역할을 수행할 수 있을 것입니다.