들어가며
GCP Serverless 서비들을를 활용한 데이터 파이프라인 구축 방법을 소개하겠습니다. 여러 GCP 서비스를 사용하여 유연하고 확장 가능한 데이터 파이프라인을 단계별로 구축해볼건데요. 이 방법을 통해 데이터 수집, 처리, 저장, 분석을 손쉽게 자동화하여 Serverless가 가진 장점을 모두가 경험해보았으면 좋겠습니다.
GCP Serverless 서비스를 이용한 데이터 파이프라인 구축해보기
Serverless 서비스를 데이터 파이프라인 중간중간에 잘 녹일 수 있는지 확인해봅시다. 
1. 데이터 수집 (Extraction)
여러 소스에서 데이터를 수집할 때는 빠르고 간단하게 구현할 수 있는 환경이 필요합니다. API로 데이터를 수집할 수 있는 플랫폼에 대해서는 여러 개의 Cloud Functions와 Cloud Scheduler, Cloud Tasks를 연결합니다. Cloud Scheduler를 설정하여 Cloud Functions를 주기적으로 실행 한 뒤, 데이터를 수집해보세요. 만약 Cloud Function의 실행 시간 제약인 540초를 넘어가게 된다면 작업을 잘게 쪼개에 Cloud Tasks에 전송하세요. Cloud Tasks 의 작업들은 각각 하나씩 Cloud Function을 배정받아 실행됩니다. 이 때 한번에 과도한 작업이 수행되지 않도록 동시성을 설정해주세요. 또한 API Limit이나 어플리케이션 상태에 의해 수집이 실패할 수 있습니다. Cloud Function 내부에 걸린 try catch 로직을 통해 실패한 작업을 확인하여 다시 Cloud Tasks에 등록하세요. 일반적인 서버 환경에서와 같이 실패한 작업을 재시도할 수 있습니다. 이렇게 하면 일시적인 네트워크 문제나 API의 일시적인 오류로 인해 데이터 수집이 중단되는 일을 방지할 수 있습니다. Google에서 제공하는 플랫폼 서비스 데이터의 경우, BigQuery의 Data Transfer 기능을 통해 데이터를 가져올 수 있습니다. 다만, API를 이용해 데이터를 가져오는 것보다 자유도는 떨어지지만 API 사용 제한없이 훨씬 안정적으로 데이터를 수집할 수 있습니다. 연동할 수 있는 플랫폼 목록은 공식 문서를 참고하세요. 링크: https://cloud.google.com/bigquery/docs/enable-transfer-service#whats_next
2. 데이터 변환 (Transform)
배치 처리를 통해 대규모 데이터 작업을 주기적으로 수행할 수 있습니다. 서버리스 환경은 필요할 때 확장되고, 사용하지 않을 때는 비용이 발생하지 않아서 효율적입니다. 서버리스의 유연성을 활용하여 데이터 정제, 변환, 집계 작업을 자동화해보세요. Cloud Tasks와 Cloud Scheduler, Cloud Function 혹은 Cloud Run을 연결하여 배치 작업을 Data Driven 아키텍쳐로 처리할 수 있습니다. 필요한 경우 추가적인 리소스를 사용하여 병렬 처리를 최적화할 수 있습니다. 예를 들어, 수집된 JSON 데이터를 CSV 형식으로 변환하거나, 특정 필드만을 추출하여 새로운 데이터셋을 만드는 작업을 할 수 있습니다. 변환된 데이터는 Cloud Storage에 저장하거나, BigQuery로 전송하여 다음 단계에서 활용할 수 있습니다.

걸 수 있는 Trigger의 종류는 다음 공식 문서를 확인해보세요 링크: https://cloud.google.com/functions/docs/calling
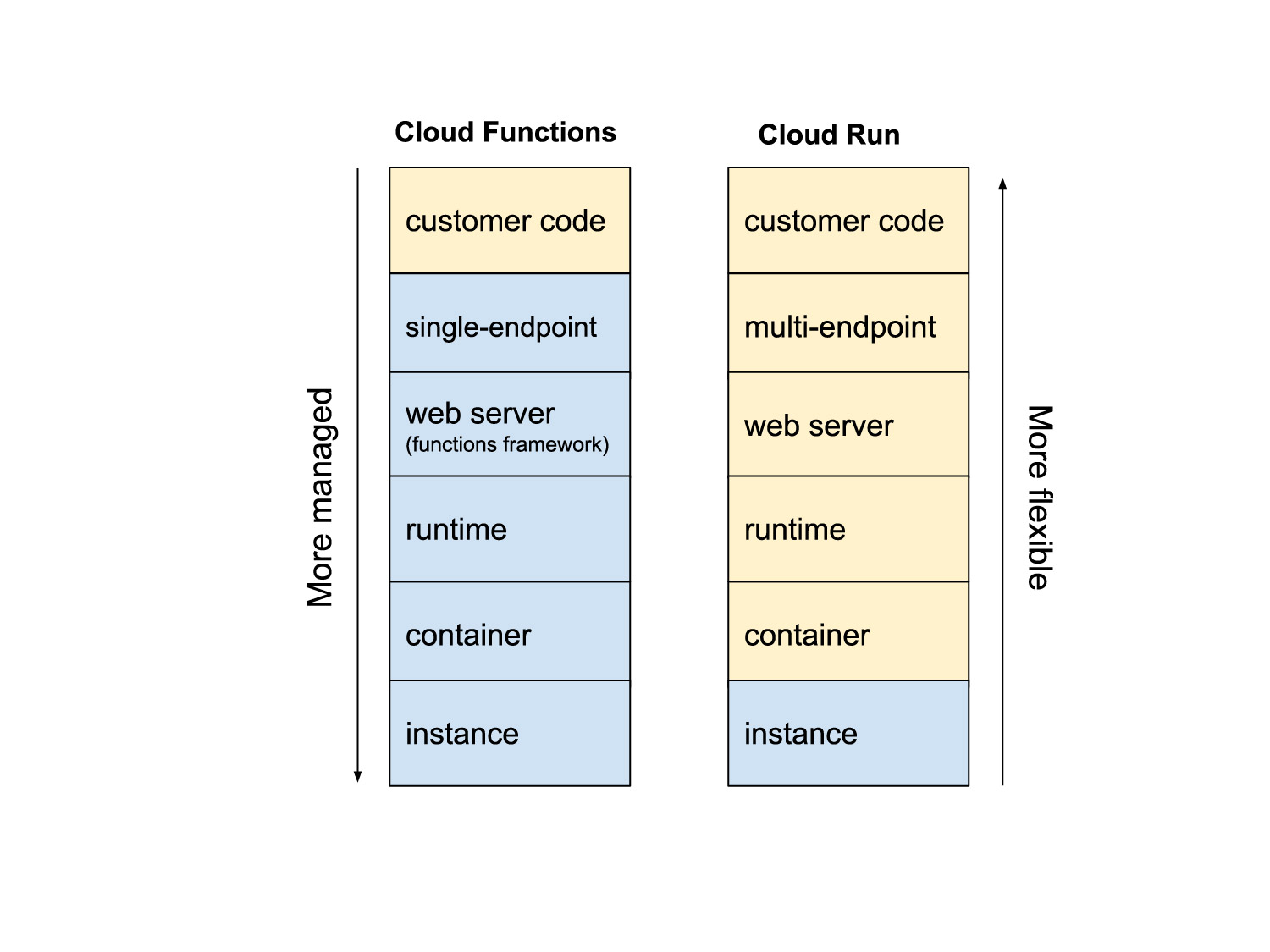
540초가 넘어가는 작업을 실행해야 하거나, Cloud Function에서 제공하는 개발 언어 외 다른 언어 작업이 필요할 경우 Cloud Function 대신 Cloud Run을 사용해보세요. Cloud Run에서는 Cloud Function에 걸려있는 제약들이 많이 사라진 채 사용할 수 있습니다. Cloud Run과 Cloud Funtion의 차이는 다음 공식 문서를 통해 더 자세히 확인해보세요 링크: https://cloud.google.com/blog/products/serverless/cloud-run-vs-cloud-functions-for-serverless?h=en
3. 데이터 저장 (Load)
BigQuery를 활용해보세요. BigQuery는 열 형식 데이터 구조를 사용하여 행 형식 데이터 구조에 비해 훨씬 빠른 속도를 보여줍니다. 여러 프로젝트를 생성하여 각 프로젝트의 BigQuery를 연속으로 쌓아 Data Lake 구조로 활용해보실 수 있습니다. BigQuery로의 데이터 추가 및 추출은 무료이며 BigQuery에 있는 데이터를 다양한 형태로 추출할 수 있습니다. 추출 시 JSON, CSV 파일 형식이 가능하며 다른 Google 서비스들과 추가 작업 없이 바로 사용할 수 있습니다.
4. 실시간 데이터 분석
서버리스 컴퓨팅은 짧은 지연 시간과 높은 대역폭으로 수십만 개의 소스에서 데이터를 실시간으로 처리할 수 있습니다. 이를 통해 몇 초 만에 유의미한 인사이트를 도출할 수 있습니다. 엔터프라이즈급 데이터 웨어하우스를 완전 관리형 서버리스로 사용할 수 있는 BigQuery와 Looker Studio를 연결해보세요. BigQuery의 연산 기능을 활용한 필터 사용이 가능할 뿐더러, 페이지 별로 빠르게 최신화가 가능합니다.
마지막으로..
GCP의 서버리스 서비스를 활용하면 데이터 파이프라인을 손쉽게 구축하고 운영할 수 있습니다. 이를 통해 실시간 데이터 분석 및 비즈니스 인사이트 도출이 가능해지며, 궁극적으로 서비스의 효율성과 경쟁력을 높일 수 있습니다. GCP의 다양한 서버리스 서비스를 적절히 조합하여 최적의 데이터 파이프라인을 설계해 보세요. 출처: https://www.redhat.com/ko/topics/cloud-native-apps/what-is-serverless https://aws.amazon.com/ko/what-is/serverless-computing/ https://devops.com/5-serverless-challenges-of-devops-teams-and-how-to-overcome-them/